Process Management와 System Call(커널 헷갈리는 개념 정리)
1. 시스템 콜의 깊은 이해
swift에서는 출력을 원할 때 print메서드를 사용합니다. 제가 만든 건 아니고 Swift 라이브러리에 구현된 함수입니다.
print는 I/O메서드입니다. (원하는 값을 출력해주기에)그런데 유저모드에서는 직접 I/O가 불가능 합니다.
그렇기 때문에 내부의 시스템 콜을 거쳐 커널에게 "화면에 출력해줘!!"라고 요청을 해야합니다.
1.1 시스템 콜 래퍼 루틴
내부에는 write() 라는 시스템 콜 래퍼가 숨어있습니다
mov eax, 4 ; write 시스템 콜 번호
mov ebx, 1 ; stdout
mov ecx, msg ; 출력할 문자열
mov edx, len ; 문자열 길이
int 0x80 ; 시스템 콜 호출!위는 예시의 어셈블리어입니다. 여기서 int 0x80은 트랩을 발생시키는 명령어로, 커널 모드로 진입해 시스템 콜을 실행하게 합니다.
중요한 부분은 시스템 콜 번호입니다.
커널이 eax 레지스터의 번호(4)를 보고 `syscall_table`이라는 테이블에서 해당 번호에 매핑된 함수의 주소를 찾아 실행합니다. 이 예시에서 4번은 write 함수죠
여기서 그러면 테이블은 누가 정해주냐!! 싶은데 운영체제를 만든 커널 개발자(또는 회사)가 정한다고 합니다.
결국 리눅스든, 유닉스든, macOS든 각각의 운영체제는 자신만의 시스템 콜 테이블을 가지고 있습니다.
내가 헷갈렸던 것 커널 VS 커널모드
커널
: 운영체제의 핵심 소프트웨어
일반적으로 메인 메모리에 잇는 것들은 SSD와 스와핑 하지만 커널은 메인 메모리에 항상 상주하는 프로그램으로
부팅이 되면 제일 먼저 메모리에 로드되어 프로세스 관리, 메모리 관리, 장치 드라이버 제어, 파일 시스템 관리, 시스템 콜 처리 등을 담당합니다.
커널 모드
운영체제는 시스템의 안전성(시스템 자원 함부로 못다루게)과 보안(일반프로그램이 하드웨어에 접근 못하게)을 유지하기 위해 유저모드와 커널모드를 구분합니다.
커널 모드에서는 프로세스 관리, 메모리 관리, 장치 드라이버 제어 등 운영체제 핵심 기능이 실행됩니다.
유저모드에서는 실행되는 애플리케이션은 커널 기능에 직접 접근할 수 없고, 시스템 콜을 통해 커널모드로 전환하여 작업을 처리해야합니다.
쉽게 말해서, 커널은 프로그램이고, 커널모드는 그 프로그램이 실행되는 CPU의 특권 상태라고 생각하면 됩니다!
모드 전환
CPU 모드 전환에 관한 것은 멀티유저일때 더 강조되어진다고 생각합니다.
만약 하나의 메모리에서 내 영역 Guest 영역으로 메모리를 나누었다고 가정해보겠습니다.
내 영역에 다른 사람이 I/O작업을 못하게 어떻게 해야할까요? (내 정보를 덮어쓰거나 이용할 수 있기에!!!☣️)
그래서 유저모드와 커널 모드를 나눴다고 생각합니다. 오직 커널 모드에서만 커널에 접근이 가능하여 파일 시스템 관리 등을 해주게 되면 멀티 유저에서도 안전하게 사용할 수 있습니다.
그러면 CPU가 명령어를 실행할때 언제 모드 비트를 체크할까요?
1. 명령어 주소를 가져올 때 (Fetch): PC에서 명령어 주소 가져올때!
- MMU가 "이 주소 접근해도 되나?" 체크
- 허용되지 않은 영역이면 -> Trap 발생
2. 명령어 해석할때 (Decode)
- 메모리에서 가져온 명령어를 op-code 분석하여 어떤 명령인지 파악하는데 어? 특권명령어(디스크 접근같이 위에서 말한 커널에서 해야하는것)이면 시스템이 이를 즉시 차단합니다.
프로세스 관리
커널의 가장 중요한 임무 중 하나가 프로세스 관리입니다.

2단계 작업
1단계: 하드웨어 관리
- CPU, 메모리, 디스크, 터미널 등 하드웨어 자원들을 초기화하고 설정
2단계: 사용자 프로그램 지원
- 하드웨어 설정이 완료된 후 사용자 프로그램들을 지원
이 과정에서 커널은 각 하드웨어와 프로세스마다 메타데이터를 관리합니다. 이게 바로 효율적인 관리의 핵심이에요!
PCB: 각 프로세스를 관리하기 위한 핵심 데이터 구조
- 프로세스 ID (PID): 프로세스를 고유하게 식별
- 우선순위 (Priority): 스케줄링을 위한 중요도
- 프로세스 상태: 실행 중, 대기 중, 준비 상태 등
- 메모리 위치 정보: 프로세스가 메모리의 어느 위치에 있는지
- 현재 디렉토리: 실행 환경의 위치
- 터미널 정보: 어떤 터미널에서 실행되고 있는지
- 열린 파일 목록: 리눅스에서는 모든 것이 파일이므로 매우 중요
- 상태 벡터 저장 영역 (State Vector Save Area): Context Switching 중에 CPU 레지스터 상태를 저장하는 공간
CPU가 어떤 프로세스를 중단할 때, 그 프로세스의 현재 CPU 상태(레지스터 값, 프로그램 카운터 등)를 State Vector Save Area에 저장한다고 생각하면 됩니다
자식 프로세스 생성 과정
컴퓨터를 부팅하면 이런 계층구조가 만들어집니다:
커널 프로세스
├── 터미널1 쉘
├── 터미널2 쉘
└── 터미널3 쉘
└── PowerPoint (쉘에서 실행)이렇게 부모-자식 관계가 생기는 이유는 새로운 프로세스를 만들 때 기존 프로세스를 복사하는 것이 효율적이기 때문입니다.

자식 프로세스 생성 4단계
Step 1: PCB 생성
- 새 PCB 공간 확보
- 부모 PCB 정보 복사 → 부모의 리소스 공유 🔄
Step 2: 메모리 공간 확보
- 자식이 들어갈 메모리 영역 찾기
- 하드웨어 메모리 리소스마다 메타데이터가 있는데 여기에 전체 크기, pid 등 정보들이 있어 이것을 통해 child process가 들어갈 영역을 찾을 수 있습니다.
- 부모 이미지(코드) 그대로 복사/ 아마 COW 기법을 사용하지 않을까 한다. 3단계에서 실제 복사하고
Step 3: 새로운 프로그램 로드
- 디스크에서 실제 실행할 프로그램 가져오기
- 복사된 이미지 위에 덮어쓰기
- 결국 자식 프로세스는 태어날때는 부모의 복사본이지만 이 과정에서 다른 사람으로 태어난다라는 개념 같습니다.
들었던 의문점..3단계에서 어차피 다른 프로세스를 자식프로세스 만드는건데 왜 복사를 하는거지?
부팅되면 제일 먼저 실행되는 프로세스를 데몬프로세스라고 부르고 PID=1입니다.
fork를 통해 부모 프로세스를 상속하고 exec를 통해 오버라이딩한다고 생각하면 될거같습니다
그렇게 되면 부모 프로세스는 기존 로직을 계속 실행하고 자식만이 완전히 원하는 프로세스가 되기 때문입니다.
Step 4: 스케줄링
- 새 프로세스 PCB를 ready 큐에 추가
- CPU 사용 대기
이 과정이 바로 fork() (1,2단계) + exec() (3,4단계)로 나뉩니다!
fork() - 똑같은 자식 만들기
int main() {
pid_t pid = fork();
if (pid == 0) {
// 자식 프로세스
printf("나는 자식!\n");
execlp("/bin/date", "date", NULL);
} else {
// 부모 프로세스
printf("나는 부모!\n");
wait(NULL);
}
return 0;
}제가 처음에 가장 신기했던 점은 fork() 한 번 호출로 두 번 리턴된다는 거였어요!
왜 그럴까요? 부모의 모든 정보(PCB, 메모리, CPU 상태)를 자식이 그대로 복사하기 때문입니다. 그래서:
- 부모: fork() 호출 후 계속 진행 → pid > 0
- 자식: fork() 호출했던 그 시점부터 시작 → pid == 0
OS가 혼동을 방지하기 위해 서로 다른 리턴값을 주는 거죠 🤝
exec() - 새로운 프로그램으로 변신
execlp("/bin/date", "date", NULL);exec 계열 함수가 호출되면:
- 현재 프로세스의 기본 정보(PID, 파일 등)만 유지
- /bin/date 프로그램을 디스크에서 로드
- 복사된 메모리 위에 덮어쓰기
- date 프로그램의 main()부터 실행
5.3 wait() - 자식 기다리기
wait(NULL); // 자식이 끝날 때까지 대기wait() 호출하면:
- 현재 프로세스 즉시 sleep 상태
- CPU를 다른 프로세스에게 양도
- 자식이 exit() 호출하면 깨어남
exit() - 깔끔하게 정리하고 알리기
exit(0); // 컴파일러가 자동으로 추가exit() 호출하면:
- 모든 리소스 해제
- 부모에게 종료 신호 전송
- 부모의 wait() 상태 해제
Context Switching 동작 원리
더 나아가 Context Switching이 실제로 어떻게 일어나는지 ls 명령어 예시로 설명해보겠습니다
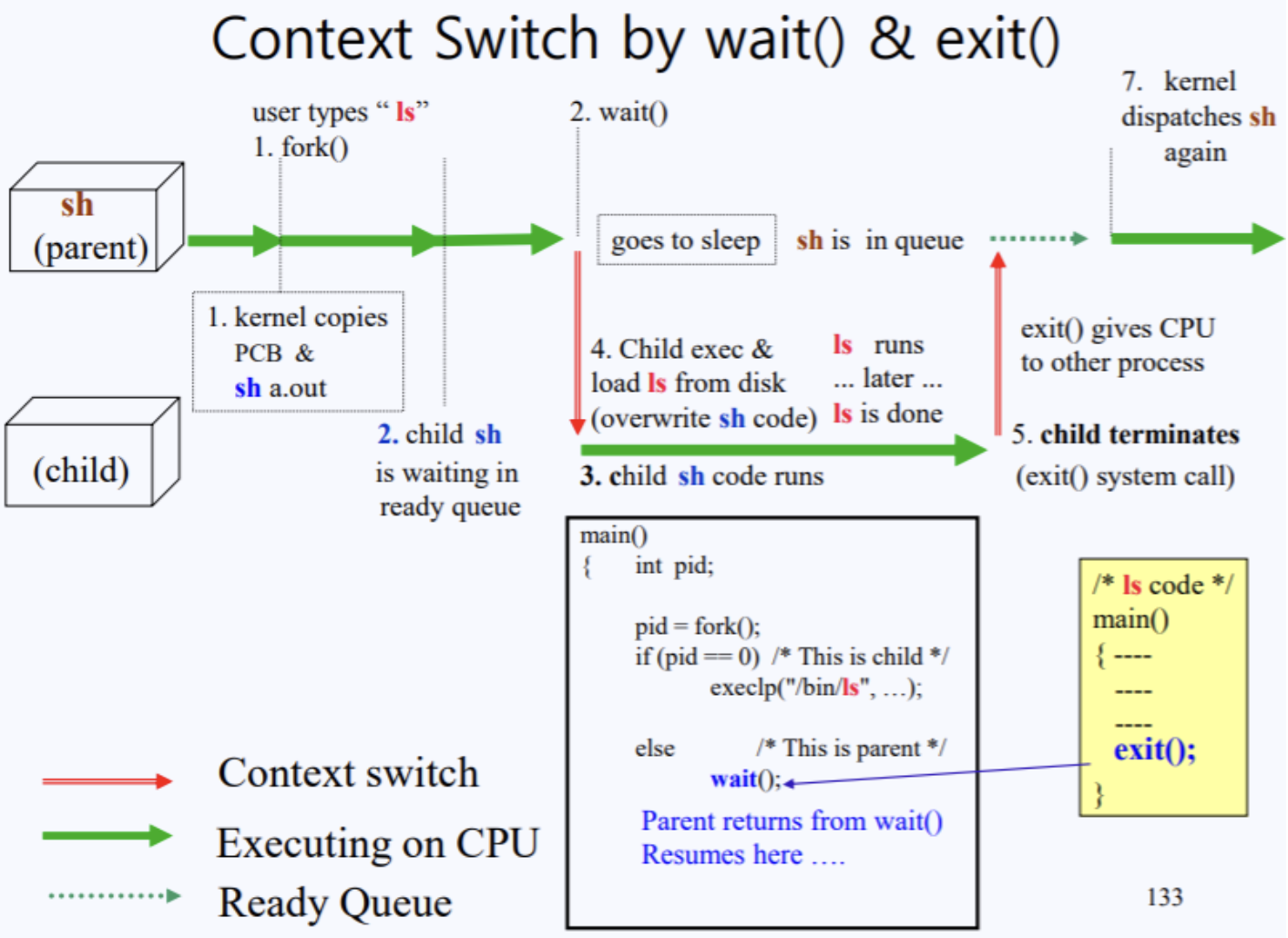
ls 명령어 실행 과정
$ ls # 터미널에서 ls 입력fork() 호출
Shell Process (PID: 100)
└── fork() 시스템 콜
└── Child Shell (PID: 200) 생성 (ready 큐 대기)wait() 호출
Parent Shell: wait() → sleep 상태
CPU 제어권: Child Shell에게 넘어감exec() 호출
Child Shell: execlp("/bin/ls", "ls", NULL)
디스크에서 ls 프로그램 로드 → 메모리에 덮어쓰기ls 실행 및 종료
ls 프로그램 main() 실행
파일 목록 출력
exit() 시스템 콜 호출부모 깨우기
Parent Shell: sleep → ready 상태
다시 사용자 입력 대기프로세스 생성 오버헤드 최적화 💡
글을 쓰고 있는 중반에 사실 예측으로 COW를 사용하겟구나...하고 넘어갔던 부분이 있어 그 부부분을 더 정리해보려 합니다,.
1. PCB 자체를 복사한다했는데 크기가 수 킬로바이라고 합니다.
2. 이미지에는 코드, 데이터, 스택 등 전체 메모리를 의하기 복사하는게 오버헤드가 일어납니다.
PCB 오버헤드 해결: 스레드(Thread)
리눅스에서 PCB는 실제로 6개 구조로 나뉘어 관리됩니다:
struct task_struct {
// Task basic info (CPU 관련 정보)
int pid;
int priority;
struct pt_regs *regs; // CPU 레지스터들
// 포인터들 (공유 가능한 자원들)
struct files_struct *files; // 열린 파일들
struct fs_struct *fs; // 파일 시스템 정보
struct tty_struct *tty; // 터미널 정보
struct mm_struct *mm; // 메모리 정보
struct signal_struct *signals; // 시그널 정보
};
왜 이렇게 나눠놨을까요? 바로 선택적 공유를 위해서입니다!
자식 프로세스가 부모와 똑같은 파일, 터미널, 메모리를 사용한다면 굳이 복사할 필요가 없잖아요. 그래서 Task basic info만 복사하고 나머지는 공유하는 방식이 바로 **스레드(Thread)**입니다!
clone() 시스템 콜
스레드는 fork() 대신 clone() 시스템 콜로 만들어집니다:
clone(10101); // binary flags
// files(1), fs(0), tty(1), mm(0), signals(1)
// 1 = 복사, 0 = 공유각 비트가 어떤 자원을 복사할지 결정하는 거예요. 모든 비트가 0이면 Light-Weight Process(LWP)가 되고, 모든 비트가 1이면 기존 fork()와 동일합니다.
필요한 만큼만 복사하고 나머지는 공유해서 오버헤드를 최소화하는 거라생각하면 될거같습니다
이미지 오버헤드 해결: Copy-on-Write (COW)
프로세스 자체를 전체 복사하는 것으로 과연할까? 그렇게 하면 오버헤드가 너무 큰데?
Page Mapping Table 공유
그래서 실제로는 이미지 자체가 아닌 페이지 매핑 테이블만 복사합니다:
부모 프로세스:
┌─────────────┐ ┌─────────────┐
│ Page Table │ -> │ Physical │
│ │ │ Memory │
└─────────────┘ └─────────────┘
자식 프로세스:
┌─────────────┐ ┌─────────────┐
│ Page Table │ -> │ Same │ <- 동일한 메모리 공유!
│ (copied) │ │ Physical │
└─────────────┘ │ Memory │
└─────────────┘이렇게 하면 실제 데이터는 하나지만 두 프로세스가 공유해서 사용하다가 실제 쓰기가 발생할때 복사하는 COW기법을 사용합니다.
불필요한 COW 최적화
그런데 또 다른 문제가 있어요. fork() 후 부모가 wait() 호출 전에 메모리에 접근하면:
pid_t pid = fork();
// 이 사이에 부모가 메모리 접근 -> 불필요한 COW 발생!
if (pid > 0) {
wait(NULL); // 늦게 호출됨
}자식은 어차피 exec()으로 메모리를 덮어쓸 건데, 부모의 메모리 접근으로 인한 COW는 완전히 의미없는 낭비죠!
우선순위 조정으로 해결
그래서 최신 시스템에서는 fork() 후 자식의 우선순위를 높여서 먼저 실행시킵니다:
기존 방식:
1. fork() -> 부모 계속 실행
2. 부모가 메모리 접근 -> 불필요한 COW
3. 나중에 자식 실행 -> exec()으로 메모리 덮어쓰기
개선된 방식:
1. fork() -> 자식 우선순위 ↑
2. 바로 자식 실행 -> exec()
3. 자식 종료 후 부모 재개이렇게 하면 불필요한 COW를 대폭 줄일 수 있어요! 정말 똑똑한 최적화라고 생각합니다 👏