외부에서 전송된 파일을 내 컴퓨터에 안전하게 저장하고 찾기 위해서는 파일 시스템이 필요합니다.
만약 파일 시스템이 없다면 어떻게 될까요? 해당 답은 이 글을 전부 다 읽고 나면 정리가 될 것입니다.
기본 개념들
파일(📁): 관련된 데이터들을 하나의 단위로 묶어서 저장한 것.
크게 2가지로 나뉩니다
1. 텍스트 파일
사람이 읽을 수 있는 문자로 구성된 파일로서 아스키 또는 UTF-8등의 문자 인코딩을 사용합니다.
우리가 자주 사용하는 메모장 혹은 vim 명령어로 직접 편집이 가능합니다.
2. 바이너리 파일
컴퓨터가 직접 해석하는 이진 데이터로 구성된 파일로 압축률이 높고 처리속도가 빠릅니다.
일반적으로 실행 파일, 이미지, 오디오, 비디오 등 모든 데이터를 의미합니다.
디렉토리(🗂️): 파일들을 논리적으로 그룹화한 컨테이너 (파일명, inode번호) 테이블로 이루어짐
사실 디렉토리도 그냥 특별한 파일입니다 리눅스의 핵심철학이 바로
Everything is a file
데이터 파일뿐만아니라 디렉토리도 파일로 간주하게 되면... 다양한 장치나 자원 일일이 다 다르게 처리할 필요없이, 그냥 어~ 너 파일이야.. 하면 파일 읽고 쓰는 함수로 모든 자원에 접근할 수 있습니다. 결국 추상화로 시스템을 단순화시켰다고 생각할 수 있을 것 같습니다.
파일 저장 방식
Contiguous Allocation (연속 할당)
파일을 디스크에 연속적으로 저장하는 방식입니다.
장점: 파일 포인터가 한 번 가리키면 연속적으로 빠르게 파일을 읽을 수 있다
단점: 파일이 삭제되면 중간중간 구멍(hole)이 생겨서 내부 단편화와 외부 단편화가 발생
제가 처음에는 "그냥 순서대로 저장하면 되는 거 아닌가?"라고 생각했는데, 실제로는 파일이 삭제되면서 생기는 조각난 공간들 때문에 문제가 생기더라고요. 그래서 디스크 조각모음이라는 게 필요한 거였어요
Scattered Allocation (분산 할당)
파일을 동일한 크기의 섹터로 조각내서 디스크에 분산 저장하는 방식입니다.
장점: 디스크 조각모음이 필요 없음, 공간 효율성이 좋음
단점: 파일 조각들을 찾기 위해 lseek() 등으로 포인터를 옮기는 딜레이 발생
현실적으로는 파티션을 나눠서 일부는 연속 할당, 일부는 분산 할당 방식을 사용하지만, 대부분은 분산 할당 방식을 사용한다고 합니다.
핵심 데이터 구조
inode:
파일의 모든 메타데이터를 담고 있는 핵심 데이터 구조입니다. 하나의 파일 = 하나의 inode예요.
- 파일 타입 및 권한(rwxrwxrwx), 소유자 사용자 아이디, 소유자 그룹, 파일 크기, 접근 수정 시간 정보 등이 담깁니다.
- 파일명은 여기서 저장하는게 아니라 우리가 위에서 했던 디렉토리에서 저장하게 됩니다. (헷갈릴수도 있어서)
- 하드링크를 통해 하나의 inode에 대해 여러 디렉토리 이름을 가질 수 있습니다.
FCB (File Control Block)
커널에서 파일 하드웨어를 관리하기 위한 메타데이터 구조체입니다. 다음과 같은 정보들이 포함되어 있어요:
- Owner: 파일 소유자
- Protection: 파일 권한
- Device: 파일이 저장된 장치 정보
- Content: 파일 내용의 위치
- Device driver routines: 디바이스별 읽기/쓰기 함수 주소
- Offset: 현재 파일의 읽기 위치
SuperBlock
파일 시스템 전체의 메타데이터를 담고 있는 구조체입니다.
포함 정보:
- 파일 시스템 전체 크기
- 루트 디렉토리 위치
- 블록/섹터 크기
- 전체 블록 수 및 사용 가능한 블록 수
- Free Block 관리 정보
특히 SuperBlock의 Free Block 관리 방식은 파일 시스템마다 달라서 호환성 문제가 있었는데, 이를 해결하기 위해 VFS(Virtual File System)가 등장했어요. (뭐 어떤데는 비트맵으로 관리하고, linkedList로 관리하고 트리형식으로 관리하여 호환성 이슈가 있었죠..)
그래서 마운트 방식으로 규격을 통일했습니다.
파일 열기 과정
먼저 디스크에서 필요한 메타데이터만 메모리로 가져오면 됩니다.
경로 탐색 과정
/a/b/c 파일을 열 때의 과정을 보면:
- 부팅 시 inode 0 (root directory)이 메모리에 올라옴
- root의 data block에서 'a' 디렉토리의 inode 번호 찾기
- 'a'의 inode를 디스크에서 메모리로 가져오기
- 'a'의 data block에서 'b' 디렉토리의 inode 번호 찾기
- 'b'의 inode를 메모리로 가져오기
- 최종적으로 'c' 파일의 inode까지 가져오기
이 과정을 Path Components라고 하는데, 매번 이렇게 하면 디스크 I/O가 너무 많이 발생해요. 그래서 등장한 게 바로...
Dentry Cache
한 번 탐색한 경로-inode 정보를 캐시에 저장해두는 시스템입니다.
예를 들어 /a/b/c를 한 번 열었다면, 다음에 /a/b/d를 열 때는 /a/b까지는 캐시에서 바로 가져올 수 있어서 훨씬 빠르게 접근할 수 있어요!
File Descriptor와 파일 접근
메타데이터 공유 문제
여러 프로세스가 같은 파일을 열 때, 동일한 메타데이터를 중복으로 가져오면 메모리 낭비가 발생합니다.
하지만 offset은 공유하면 안 되죠! 각 프로세스마다 파일의 다른 위치를 읽고 있을 수 있으니까요.
해결책: 구조체 분리
그래서 파일 메타데이터를 두 개의 구조체로 분리했습니다:
1. inode struct: 모든 프로세스가 공유하는 메타데이터 2. file struct: 각 프로세스가 개별로 가지는 offset 정보
File Descriptor 작동 방식
int fd = open("/a/b/c", O_RDONLY);
read(fd, buffer, size);- open() 시에만 파일 경로명을 사용해 inode 정보 설정
- 프로세스의 PCB에 있는 u_ofile[] 배열에 file 구조체 주소 저장
- 배열의 인덱스가 바로 File Descriptor(fd)
- read(), write(), close()는 모두 fd로만 접근
왜 open 이후로는 fd만 사용할까요?
매번 경로명으로 접근하면 Path Components 과정을 반복해야 해서 디스크 I/O가 너무 많이 발생하기 때문이에요.
fd로 접근하면 file struct → inode struct → device switch 3번의 메모리 접근만으로 모든 정보를 얻을 수 있습니다!
VFS와 다양한 파일 시스템


호환성 문제
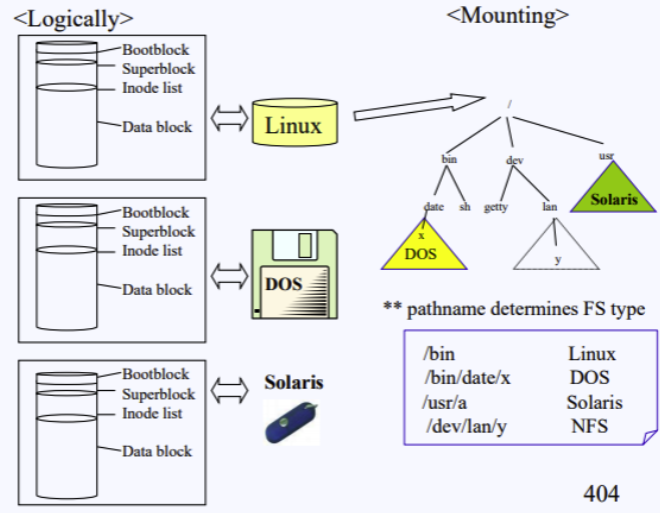
예전 유닉스 환경에서는 오직 유닉스 파일 시스템만 마운트가 가능했어요. 윈도우, 솔라리스 등 다른 파일 시스템은 서로 호환되지 않았죠.
VFS의 등장
리눅스는 VFS(Virtual File System)라는 추상화 계층을 도입해서 이 문제를 해결했습니다!
VFS 덕분에 ext4, NTFS, FAT32, NFS 심지어 윈도우나 Solaris 파일 시스템까지도 마치 하나의 일관된 방식으로 접근할 수 있게 되었어요.
예를 들어:
- /a/b가 윈도우 파일 시스템에 마운트
- /x/y가 Solaris 파일 시스템에 마운트
이런 상황에서도 cp /a/b/c /x/y/z 같은 명령으로 서로 다른 파일 시스템 간 복사가 가능합니다!
VFS Standard Objects
리눅스는 파일 시스템이 무엇이든 상관없이 4가지 표준 객체를 정의합니다:
- Superblock object: 파일 시스템 전체 구조
- inode object: 각 파일 구조
- file object: 실제 데이터
- dentry object: 경로명에 매핑된 inode 정보 (캐시 역할)
주요 파일 시스템 비교
Windows: FAT → NTFS

FAT:
- 링크드 리스트 방식으로 클러스터 관리
- 파일 최대 크기 4GB 제한
- 보안 기능 없음
- USB 등에서 주로 사용
NTFS:
- 대용량 파일/디스크 지원 (이론상 16 엑사바이트)
- 저널링 기능으로 데이터 안정성 향상
- 파일별 권한 설정 가능
macOS: HFS → APFS

APFS의 특징:
- 동적 볼륨 공유: 컨테이너 내에서 볼륨들이 공간을 유연하게 공유
- COW (Copy-On-Write): 메타데이터만 복사하고 실제 수정 시에만 새 데이터 생성
- 스냅샷: 특정 시점의 파일 상태 저장 (타임머신 백업)
그런데 macOS에서 한글 파일명이 깨지는 이슈가 있죠? 이게 바로 파일 시스템 때문이에요!
정규화 이슈:
- macOS는 NFD 방식: "가.txt" = "ㄱ + ㅏ.txt" (분해)
- Windows/Linux는 NFC 방식: "가.txt" = "가.txt" (조합)
Apple이 유니코드 도입 당시 표준이 NFD였어서 그대로 사용하다 보니 호환성을 위해 계속 유지하고 있다고 해요.
Linux: ext4

ext4 구조: 부팅 관련 MBR을 제외하고 블록 그룹(128MB)으로 나뉘며, 각 블록 그룹은 6가지 정보를 담고 있습니다:
- SuperBlock: 전체 파일 시스템 메타데이터
- Group Descriptor: 각 블록 그룹의 위치 정보 (목차 역할)
- 블록 비트맵: 데이터 블록 사용 상태
- inode 비트맵: inode 할당 상태 관리
- inode Table: 파일과 디렉토리의 메타데이터
- Data Blocks: 실제 파일 내용 저장
파일 생성 과정:
- inode 비트맵에서 빈 자리 찾아 할당
- 블록 비트맵에서 빈 블록 찾아 할당
- inode에 메타데이터 설정
- 부모 디렉토리에 (파일명, inode번호) 엔트리 추가
'CS' 카테고리의 다른 글
| Process Management와 System Call(커널 헷갈리는 개념 정리) (2) | 2025.07.22 |
|---|---|
| 프로세스 메모리 (Swift의 heap은?) (1) | 2024.06.15 |